



Home / News / Events / Events detail
On November 10, Viva Biotech, in collaboration with Greater Neo Bay · Guosheng Health Park, successfully organized the "Pharmaceutical Big Data Empowering Innovative Drug R&D" salon, both online and offline. The event brought together industry experts and pioneers to discuss the revolutionary impact of pharmaceutical big data and AI technology in the field of small molecule drug development, offering insights from a broader perspective and multiple dimensions. Together, they envisioned the next golden era of small molecule drugs discovery.
Ms. Baoyu Wang, Deputy General Manager of Greater Neo Bay · Guosheng Health Park, Dr. Ligang Zhao, General Manager Assistant, and Mr. Zhengyin Zhu, Director of Business Development and Operations, attended this salon. Mr. Zhengyin Zhu delivered the opening speech, followed by the main segment of theme sharing. Here we have gathered some fascinating viewpoints shared by the guests for our readers’ enjoyment.
To watch the full video playback, please visit "Viva Biotech" Wechat Channel or Bilibili
Can DNA-encoded Molecular Library (DEL) Decode the FIC Drug Discovery?

Bing Xia, Ph.D.
Vice President of Viva Biotech
In 1992, The Nobel laureates in Physiology and Medicine, Sydney Brenner and Richard Lerner, first proposed the concept of DNA Encoded Library (DEL). Since then, DEL technology has undergone significant advancements over the course of more than a decade, emerging as a prominent pillar in drug discovery. Dr. Xia comprehensively introduced the development steps of DEL technology, starting from library construction, affinity screening, high-throughput sequencing, data analysis, off-DNA re-synthesis and testing, and hit confirmation. He emphasized the synthesis method "Split & Pool" used in library construction, the experimental steps of affinity screening, and its advantages. Compared to traditional screening methods, DEL Libraries offer high-quality and diverse libraries, molecular diversity, shorter R&D cycles, and lower costs, with the ability to screen complex protein targets. Additionally, integrating CADD and AIDD into DEL technology, along with the development of various DNA-compatible chemical reactions, further enables rapid, efficient, and proliferative effects of DEL technology. He then presented several successful cases demonstrating the wide application of DEL technology in FIC drug discovery. Dr. Xia pointed out that Viva Biotech's recently launched V-DEL technology platform, led by him, will establish various types of high-quality DEL libraries. By integrating efficient screening methods with technology platforms such as SBDD/FBDD, ASMS, SPR, and incorporating the comprehensive one-stop drug discovery platform of Viva Biotech, it will provide comprehensive and differentiated services for DEL-based drug discovery, including target protein production, DEL library construction, affinity screening, customized synthesis of active compounds, and biological assay validation.
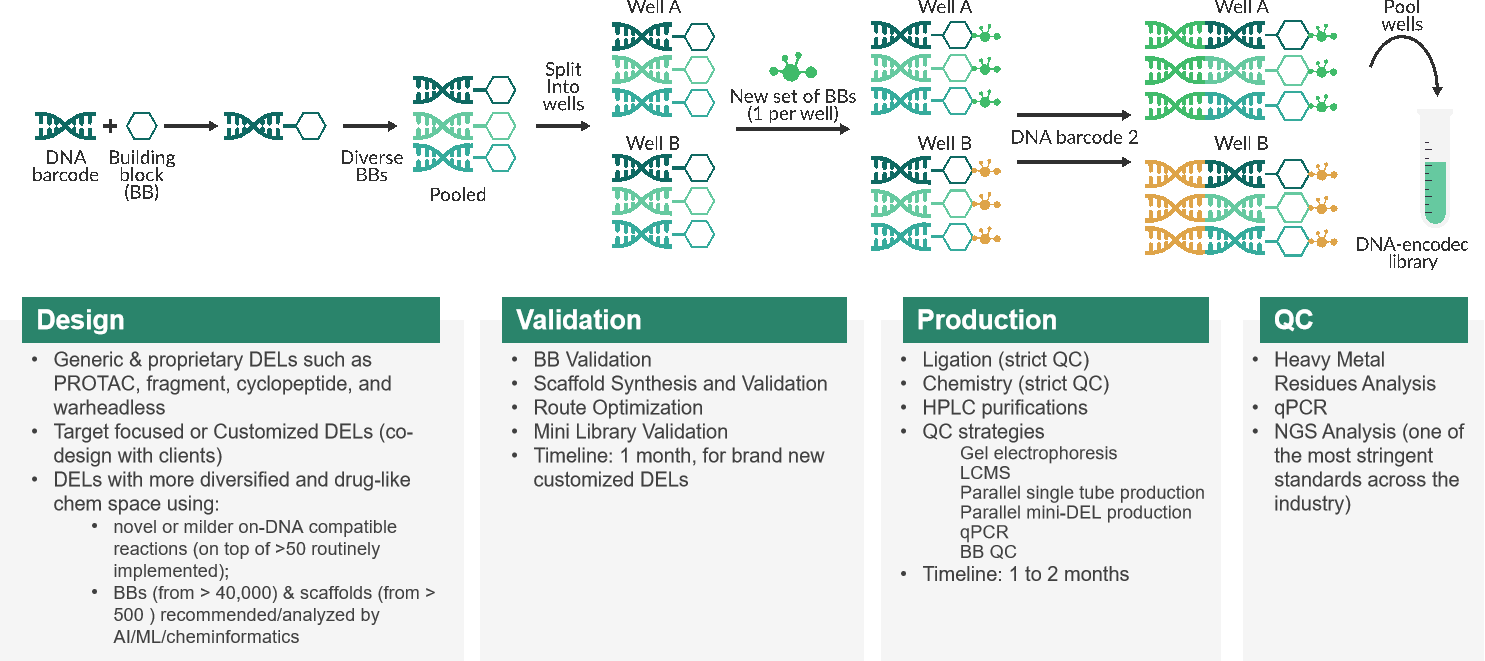
(High-quality V-DEL libraries construction process)
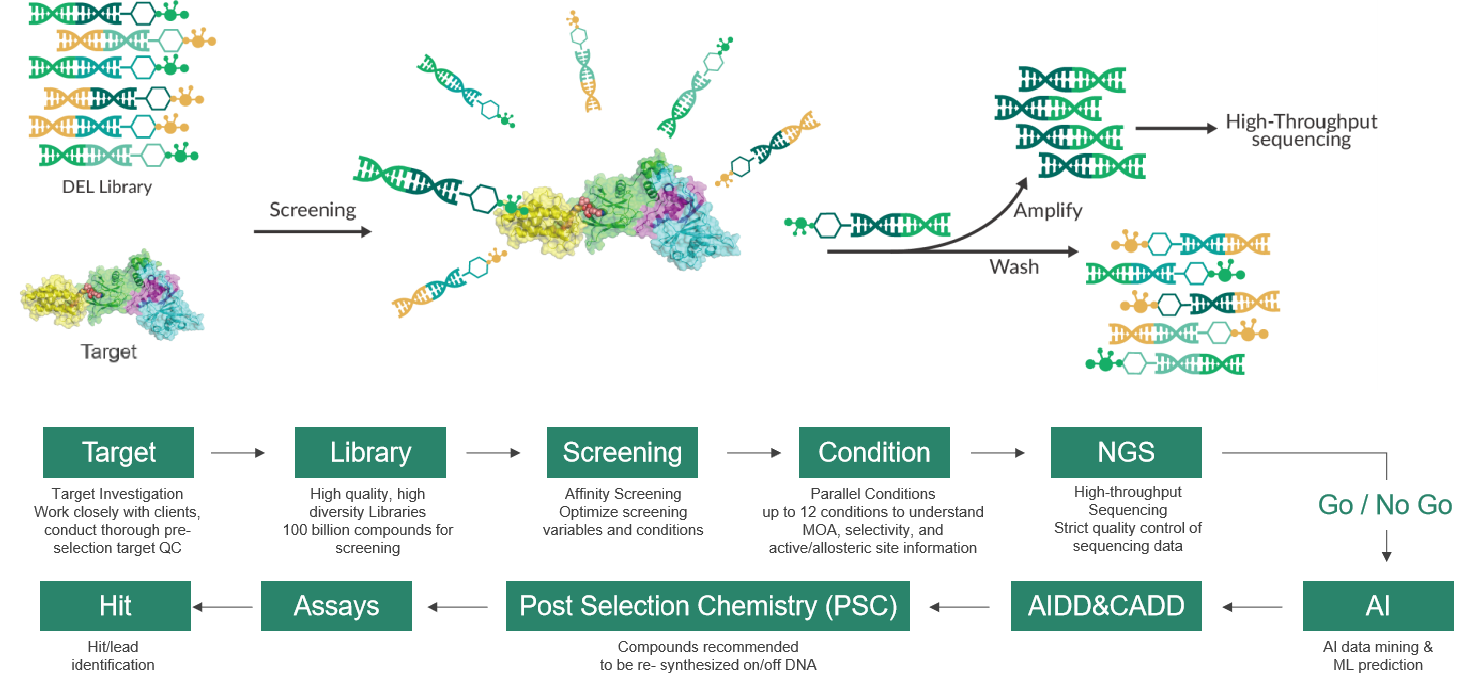
(Efficient V-DEL screening process)
Protein Engineering and de novo Design with Geometric Deep Learning

Bingxin Zhou, Ph.D.
Research Asistant, Institute of Natural Sciences, Shanghai Jiao Tong University
Dr. Zhou introduced her research progress and insights in protein design and engineering from the perspective of computer science in the past year. Firstly, she explained protein design tasks in synthetic biology, providing a comprehensive overview of the comparison between artificial intelligence-assisted methods and traditional experimental methods, protein prediction, protein structure expression, structure data encoders, graphical representation methods for biological data, and graph representation learning.
She further shared research achievements obtained by transforming proteins into graphs and applying deep learning algorithms from a wet lab perspective. By presenting multiple protein and demand improvement case studies, she illustrated the application of lightweight protein engineering tools. Additionally, she discussed another research outcome based on a graph neural network framework for de novo design of protein sequences. The research team employed a diffusion generative method similar to image generation principles to design restriction endonucleases. In comparison with existing methods such as RFdiffusion and ProGen, the method employed by their team resulted in novel proteins with sequence lengths of up to 800, whereas the other two methods achieved lengths of 100-400 and 140 respectively. Additionally, the success rate of the newly obtained proteins in terms of improved activity compared to the wild-type was 74%, while the success rates for the other two methods were 10-20% and 40%. Finally, Dr. Zhou compared the differences between the designed proteins and the wild-type proteins from various angles, including cleavage activity and thermal stability, inference of hidden sequence information, and diversity versus high sequence recoverability. These comparisons further demonstrated the superiority of protein design and engineering based on geometric deep learning models.
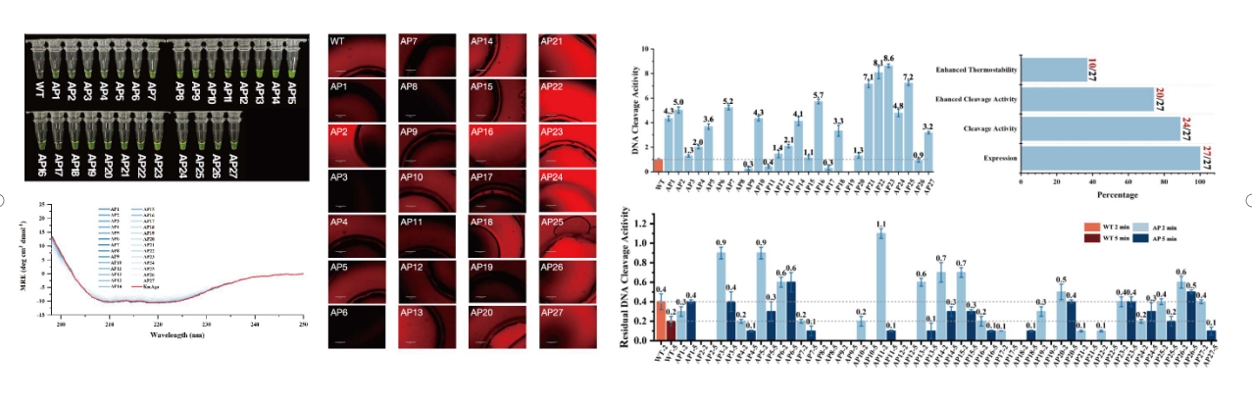
(Case Study: A Comparison of Cleavage and Thermostability)
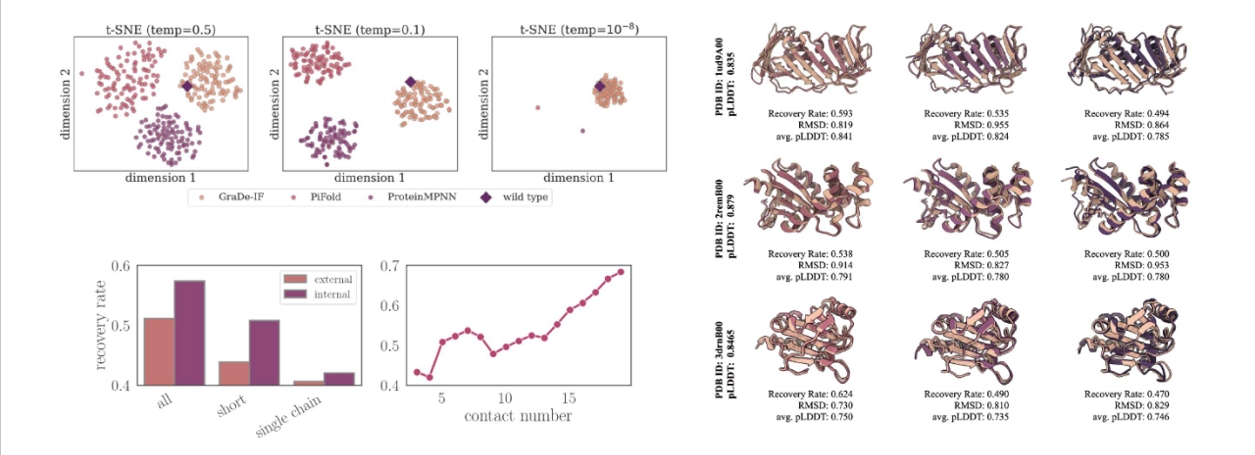
(Case Study: Inference of Hidden Sequence Information)
(Case Study: Diversity vs. High Recovery Rate)
Roundtable Discussion
New Paradigm in Pharmaceutical R&D: How Big Data and AI Empower New Drug Discovery

(From left to right: Dr. Yue Qian, Senior Director of Computational Chemistry at Viva Biotech; Dr. Zhen Min, Founder and CEO of BioCasting; Dr. Sheng Wang, CEO of Zelixir Biotech; Ms. Shiyu Lin, Director of External Cooperation at DP Technology; Dr. Jue Wang, Senior Director of Business Development at Insilico Medicine.)
Q1: Currently, AI-driven drug discovery primarily involves three business modes: AI-biotech, AI-CRO, and AI pipeline. With the continuous evolution of big data, a fourth commercial model has emerged, which is based on big data companies, such as the well-known AI pharmaceutical company Recursion. What do you think are the differences between this fourth model and the previous three, and how does it contribute to drug discovery?
Dr. Zhen Min: I strongly resonate with Recursion’s slogan “Decoding Biology To Radically Improve Lives.” Recursion goes back to the fundamental question of drug discovery, which is to answer pharmacology, efficacy, toxicology, and their impact on diseases from a biological perspective. What sets Recursion apart, in my opinion, is its ability to bridge the gap between wet lab and dry lab. Recursion also places great emphasis on the relevance of data, particularly the strong correlation between data generated from the chemistry and biology platforms.
Dr. Sheng Wang: It is widely acknowledged that data is crucial for AI. With data, scientists can build models and generate new paradigms for understanding data, thereby driving progress and development in the scientific community. Especially in the era of biology, fields such as biotechnology, bioengineering, AI pharmaceuticals, CADD, and synthetic biology have accumulated vast amounts of data. The challenges for AI lie in understanding multimodal data and developing appropriate and simplified modeling approaches. Overcoming this challenge may potentially usher in the third revolution of AI.
Ms. Shiyu Lin: Data is indeed crucial for AI. We often encounter clients asking what to do if there is insufficient data for AI, especially in the field of biomedicine where certain data can be extremely scarce and may be controlled by a few pharmaceutical giants. This is a prevalent problem in the industry, and also a challenge faced by the first three models. Recursion offers a clever solution to this problem, and there are also research teams in the United States and Canada attempting to address data scarcity through geometric deep learning, synthetic data, zero-shot machine learning, and other methods. These are meaningful explorations.
Dr. Jue Wang: Whether in AI or scientific research, it is widely recognized that data is invaluable. However, the prerequisite for achieving this is a significant investment of resources. For example, companies like Recursion have invested heavily in accumulating massive amounts of data, but this approach may not be feasible for every company. In the case of Biotech, it is essential to have a clear understanding of the company's technological strengths and expertise, while considering the company strategy and business model that can provide long-term development opportunities. Taking InSilico Medicine as an example, we initially collaborated with numerous research institutions and large pharmaceutical companies to gather valuable data and collaboration experiences through algorithms. As the algorithms gradually matured, they were transformed into software solutions, then directly providing software services to customers. Additionally, they could apply the algorithms to their own pipeline for license-out.
Q2: Recently, DeepMind has launched a new version of the AlphaFold model, known as AlphaFold 3. It is said to go beyond protein folding and can generate highly accurate structure predictions in ligands, proteins, nucleic acids, and post-translational modifications. This system has been applied to drug design. What do you think is the most significant characteristic of this tool? Are there any limitations? And what is its guiding role in drug design?
Dr. Wang Sheng: AlphaFold 3 represents a remarkable leap from its predecessor, as it can now predict the interactions between proteins and any other biomolecule, which is a significant advancement. Those familiar with AlphaFold 2 would know that the underlying logic of this tool is co-folding, and once this logic is understood, it naturally extends to protein-protein, protein-peptide, and protein-nucleic acid interactions. For AlphaFold 2, in addition to its concept, its strength lies in engineering capabilities, computational power, and infrastructure. Additionally, the recruitment of top talent has been a driving force behind the success of AlphaFold 2.
Dr. Jue Wang: When AlphaFold was first introduced, it shocked the field of AI pharmaceuticals like an earthquake. For a target with limited structural information, conventional approaches might involve methods such as DEL or high-throughput screening. However, with accurate structural information, molecular generation can be achieved through AI, which is opening up a completely new pathway for the industry. Moreover, the higher the accuracy of the predicted structures, the higher the probability of generating active molecules, which undoubtedly brings great benefits to the entire drug discovery process.
Q3: What are the distinctive features of CADD and AIDD compared to traditional drug design? Where does their novelty lie, and how do they differ from an experienced medicinal chemist?
Dr. Jue Wang: Initially, there were high expectations that AI would bring disruptive impact to the industry. However, AI is more of a tool to assist scientists and is currently unable to replace them within the foreseeable timeline in practice. Therefore, InSilico Medicine empowers and accelerates drug discovery by enabling scientists to make full use of this tool. AI's learning is based on the data and knowledge accumulated by scientists, so the results generated through AI applications are likely to be similar to those of scientists or in line with logical knowledge.
Ms. Shiyu Lin: CADD/AIDD has remained a support tool in recent years and has proven to be beneficial for researchers who are new to the field. Its novelty lies in two aspects. Firstly, in molecular design, it provides scientists with more comprehensive and expansive perspectives. Secondly, in terms of activity validation, computational methods can be combined with experimental approaches, enhancing decision-making efficiency and the quality of experiments.
Dr. Sheng Wang: CADD/AIDD may only account for a maximum of 15% of the entire pharmaceutical process. It can assist in identifying lead compounds or hit compounds, but these molecules are still far from becoming oral drugs. A series of in vitro experiments, animal testing, toxicity assessments, and clinical trials are required, each of which involves significant time, personnel, and financial resources. These are substantial obstacles that AI faces in the pharmaceutical industry.
Q4: Currently, the models used in drug design still require a significant amount of manual intervention and expert involvement. In light of this, what breakthroughs do you think these AI tools bring to truly achieve intelligence?
Dr. Min Zhen: One major bottleneck in the current development of AI lies in the lack of data, both in terms of biological and chemical data. Taking Recursion as an example, as of September 30th this year, they have accumulated 23 petabytes of data through billions of experiments and screened six million molecules. This massive data accumulation has enabled the application of AI tools. Therefore, high-quality data is the prerequisite and foundation for training AI.
To learn more, please visit: https://www.vivabiotech.com or reach out to our expert team via email at info@vivabiotech.com.